Pandas简介
Pandas是一个开放源码的Python库,它使用强大的数据结构提供高性能的数据操作。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷处理数据的函数和方法;
Pandas用于广泛的领域,包括金融、经济、统计、分析等学术和商业领域。
Pandas特点
- 快速高效的DataFrame对象,具有默认和自定义索引;
- 将数据从不同文件格式加载到内存中的数据对象的工具;
- 基于标签的切片、索引和大数据集子集;
- 删除或插入来自数据结构的列;
- 按数据分组进行聚合及转换;
- 高性能合并及数据加入;
- 时间序列;
Pandas数据结构
Series:一维数组,与Numpy中的一维array类似,与Python基本数据结构List也相近;Series可以保存不同数据类型,如字符串、Boolean、数字等;大小不可变;Time-Series:以时间为索引的Series;DataFrame:二维的表格型数据结构,可以理解为Series的容器;大小可变;Panel:三维数组,可以理解为DataFrame的容器;大小可变;Series序列
构造函数
pandas.Series(data, index, dtype, copy) # data: 支持多种数据类型,如 ndarray、list、constants # index:索引值必须唯一,与data长度相同,默认为np.arange(n) # dtype:数据类型 # copy:是否赋值数据,默认为false
Series创建
创建空的Series
import pandas as pd s = pd.Series() print(s) # 执行结果如下 Series([], dtype: float64)从ndarray创建一个Series
# 如果数据是ndarray,则传递的索引必须具有相同的长度;如果没有传递索引值,那么默认的索引范围为range(n),其中n为数组的长度 import pandas as pd import numpy as np data = np.array(['a','b','c','d']) # 不传索引值,采用默认索引值0 ~ len(data)-1 s = pd.Series(data) print(s) # 执行结果如下 0 a 1 b 2 c 3 d dtype: object # 传递索引值 s = pd.Series(data,index=[100,101,102,103]) print(s) # 执行结果如下 100 a 101 b 102 c 103 d dtype: object从字典创建一个Series
# 字典作为输入传递,如果没有指定索引,则按排序从字典中提取键值作为索引,如果传递了索引,则按照索引顺序从字典中提取数值; import pandas as pd import numpy as np data = {'a':0, 'b':1, 'c':2, 'd':3} # 不传索引 s=pd.Series(data) print(s) # 执行结果如下 a 0 b 1 c 2 d 3 dtype: int64 # 传递索引,索引值为字典的key,如不存在则对应值为NaN填充 s=pd.Series(data,index=['a','c','d','e']) print(s) # 执行结果如下 a 0.0 c 2.0 d 3.0 e NaN dtype: float64从常量创建一个Series
# 当数据是常量时,必须提供索引,索引数量为该常量重复次数 import pandas as pd import numpy as np s = pd.Series(1, index=[0,1,2,3]) print(s) # 执行结果如下 0 1 1 1 2 1 3 1 dtype: int64
Series访问
- 根据索引位置访问
import pandas as pd s=pd.Series([1,2,3,4,5],index=['a','b','c','d','e']) # 访问第一个元素 print(s[0]) # 输出结果如下 1 # 访问前三个元素 print(s[:3]) # 输出结果如下: a 1 b 2 c 3 dtype: int64
s[a:] 为提取该索引后所有数据
s[a:b]为提取a和b索引之间的所有数据
- 根据索引访问数据
import pandas as pd s=pd.Series([1,2,3,4,5],index=['a','b','c','d','e']) # 访问指定索引数据 print(s[a]) # 输出结果如下 1 # 访问多个索引数据 print(s[['a','c']]) # 输出结果如下 a 1 c 3 dtype: int64
访问不存在索引将会抛出
KeyError错误
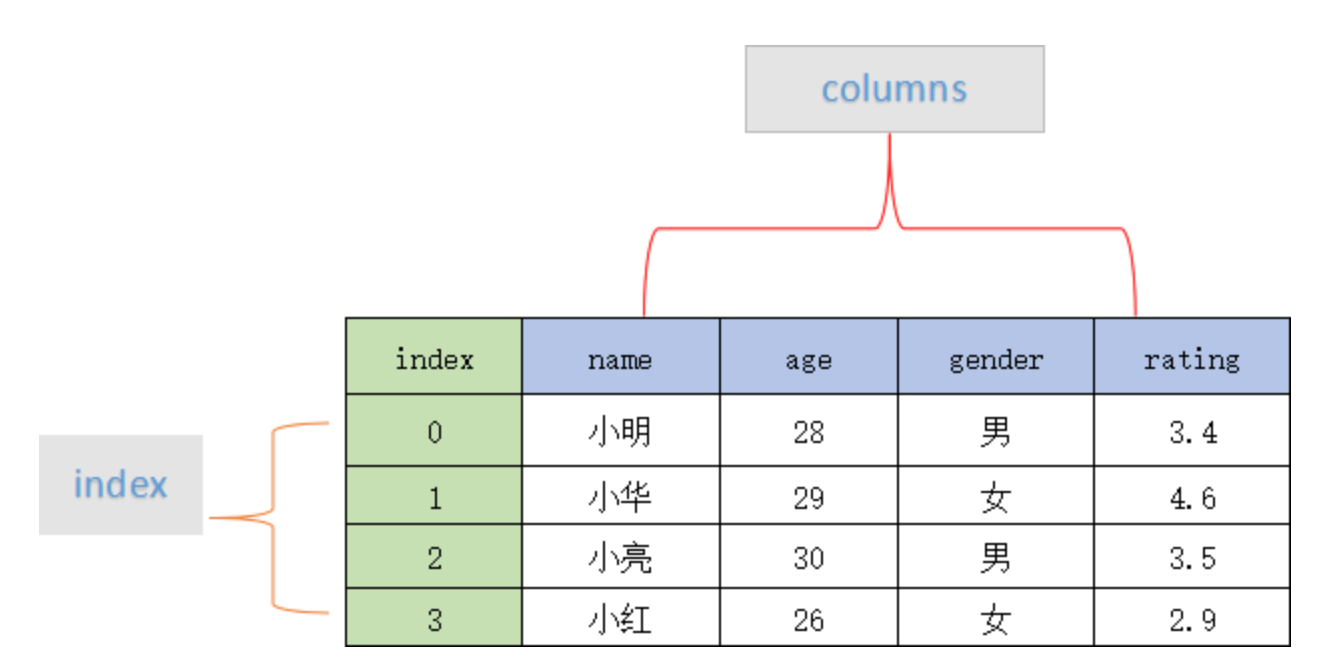
DataFrame数据帧
DataFrame是二维的数据结构,它包含一组有序的列,每列可以是不同的数据类型,DataFrame既有行索引,也有列索引,它可以看成是Series组成的字典,不过Series公用一个索引;
DataFrame的功能特点为:
- 不同列可以是不同数据类型;
- 大小可变;
- 含有行索引与列索引;
- 可以对行和列执行算术运算;
构造函数
pandas.DataFrame(data, index, columns, dtype, copy)
# data: 支持多种数据类型,如ndarray、series、map、lists、dict、constant或DataFrame
# index:行标签,如果没有传递索引值,默认为np.arrange(n)
# columns:列标签,如果没有传递索引值,默认为np.arrange(n)
# dtype:每列的数据类型
# copy:是否赋值数据,默认为FalseDataFrame创建
创建一个空的DataFrame
import pandas as pd df = pd.DataFrame() print(df) # 执行结果如下 Empty DataFrame Columns: [] Index: []从列表创建DataFrame
import pandas as pd # 一维列表 data = [1,2,3,4,5] df = pd.DataFrame(data) print(df) # 执行结果如下 0 0 1 1 2 2 3 3 4 4 5 # 二维列表,指定列名 data = [['Alex',10], ['Bob',20],['Clarke',13]] df = pd.DataFrame(data,columns=['Name','Age']) print(df) # 执行结果如下 Name Age 0 Alex 10 1 Bob 20 2 Clarke 13 # 二维列表指定数据类型,指定数据类型会将数值类型转换为dtype指定的类型 df = pd.DataFrame(data, columns=['Name','Age'], dtype=float) print(df) # 执行结果如下 Name Age 0 Alex 10.0 1 Bob 20.0 2 Clarke 13.0从字典创建DataFrame
import pandas as pd # 字典中的列表长度需保持一致 data = {'Name': ['Tom', 'Jack', 'Steve', 'Ricky'], 'Age': [23,26,19,30]} df = pd.DataFrame(data) print(df) # 执行结果如下 Name Age 0 Tom 23 1 Jack 26 2 Steve 19 3 Ricky 30 # 使用列表作为索引 df = pd.DataFrame(data, index=['rank1', 'rank2', 'rank3', 'rank4']) print(df) # 执行结果如下 Name Age rank1 Tom 23 rank2 Jack 26 rank3 Steve 19 rank4 Ricky 30从字典列表创建DataFrame
import pandas as pd data = [{'a':1,'b':2},{'a':10,'b':20,'c':30}] df = pd.DataFrame(data) print(df) # 执行结果如下 a b c 0 1 2 NaN 1 10 20 30.0 # 传入索引及列名,指定索引在字典key中不存在时,则数据为NaN df = pd.DataFrame(data, index=['1st','2nd'], columns=['a','aa']) print(df) # 执行结果如下 a aa 1st 1 NaN 2nd 10 NaN从Series创建DataFrame
import pandas as pd data = {'one': pd.Series([1,2,3],index=['a','b','c']), 'two': pd.Series([10,20,30,40], index=['a','b','c','d'])} df = pd.DataFrame(data) print(df) # 执行结果如下,第一列会自动转换为浮点数 one two a 1.0 10 b 2.0 20 c 3.0 30 d NaN 40
DataFrame操作
DataFrame读取列
import pandas as pd data = {'one': pd.Series([1,2,3], index=['a','b','c']), 'two': pd.Series([10,20,30,40], index= ['a','b','c','d'])} df = pd.DataFrame(data) # 读取一列 print(df['one']) # 执行结果如下 a 1.0 b 2.0 c 3.0 d NaN Name: one, dtype: float64 # 读取多列 print(df[['one','two']]) # 执行结果如下 one two a 1.0 10 b 2.0 20 c 3.0 30 d NaN 40DataFrame添加列
import pandas as pd data = {'one': pd.Series([1,2,3], index=['a','b','c']), 'two': pd.Series([10,20,30,40], index= ['a','b','c','d'])} df = pd.DataFrame(data) # 添加列 df['three'] = pd.Series([100,200,300], index=['a','b','c']) print(df) # 执行结果如下 one two three a 1.0 10 100.0 b 2.0 20 200.0 c 3.0 30 300.0 d NaN 40 NaN # 列计算 df['four'] = df['one'] + df['three'] print(df) # 执行结果如下 one two three four a 1.0 10 100.0 101.0 b 2.0 20 200.0 202.0 c 3.0 30 300.0 303.0 d NaN 40 NaN NaNDataFrame删除列
import pandas as pd data = {'one': pd.Series([1,2,3], index=['a','b','c']), 'two': pd.Series([10,20,30,40], index= ['a','b','c','d'])} df = pd.DataFrame(data) del df['one'] print(df) # 执行结果如下 two a 10 b 20 c 30 d 40DataFrame读取行
import pandas as pd data = {'one': pd.Series([1,2,3], index=['a','b','c']), 'two': pd.Series([10,20,30,40], index= ['a','b','c','d'])} df = pd.DataFrame(data) # 通过loc函数接收行索引查询行,并将结果进行转置 ## 查询索引编号为b的行 print(df.loc['b']) # 执行结果如下 one 2.0 two 20.0 Name: b, dtype: float64 # 通过iloc函数接收行索引位置查询行,并将结果转置 ## 查询第4行 print(df.iloc[3]) # 执行结果如下 one NaN two 40.0 Name: d, dtype: float64 # 通过切片查询多行 ## 查询第2至第4行(不含第4行) print(df[1:3]) # 执行结果如下 one two b 2.0 20 c 3.0 30DataFrame添加行
import pandas as pd df = pd.DataFrame([[1,2],[3,4]], columns = ['a','b']) df2 = pd.DataFrame([[5,6],[7,8]],columns = ['a','b']) # 类似数据库表插入 df = df.append(df2) print(df) # 执行结果如下 a b 0 1 2 1 3 4 0 5 6 1 7 8DataFrame删除行
import pandas as pd df = pd.DataFrame([[1,2],[3,4]], columns = ['a','b']) df2 = pd.DataFrame([[5,6],[7,8]],columns = ['a','b']) df = df.append(df2) # 删除行索引为0的行 df = df.drop(0) print(df) # 执行结果如下 a b 1 3 4 1 7 8
DataFrame属性和方法
DataFrame常用属性和方法如下:
T:转置行与列;axes:返回一个列,行轴标签与列轴标签为唯一成员;dtypes:返回对象中的数据类型;empty:如果DataFrame为空,则返回True,即任何轴的长度均为0;shape:返回表示DataFrame的维度的数组;数组第一个元素为行数,第二个元素为列数;size:DataFrame中的元素个数;head:返回开头前N行;默认为5行;tail:返回最后N行;默认为5行;
T方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24,26,27,33,22]),
'Rating': pd.Series([4.23,3.33,4.11,4.66,5.24])}
df = pd.DataFrame(data)
print(df)
print('******************')
print(df.T)
# 执行结果如下
Name Age Rating
0 Tom 24 4.23
1 James 26 3.33
2 Ricky 27 4.11
3 Vin 33 4.66
4 Steve 22 5.24
******************
0 1 2 3 4
Name Tom James Ricky Vin Steve
Age 24 26 27 33 22
Rating 4.23 3.33 4.11 4.66 5.24axes方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24,26,27,33,22]),
'Rating': pd.Series([4.23,3.33,4.11,4.66,5.24])}
df = pd.DataFrame(data)
print(df)
print('******************')
print(df.axes)
# 执行结果如下
Name Age Rating
0 Tom 24 4.23
1 James 26 3.33
2 Ricky 27 4.11
3 Vin 33 4.66
4 Steve 22 5.24
******************
[RangeIndex(start=0, stop=5, step=1), Index(['Name', 'Age', 'Rating'], dtype='object')]
dtypes方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24, 26, 27, 33, 22]),
'Rating': pd.Series([4.23, 3.33, 4.11, 4.66, 5.24])}
df = pd.DataFrame(data)
print(df.dtypes)
# 执行结果如下
Name object
Age int64
Rating float64
dtype: objectempty方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24, 26, 27, 33, 22]),
'Rating': pd.Series([4.23, 3.33, 4.11, 4.66, 5.24])}
df = pd.DataFrame(data)
print(df.empty)
# 执行结果如下
Falseshape方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24, 26, 27, 33, 22]),
'Rating': pd.Series([4.23, 3.33, 4.11, 4.66, 5.24])}
df = pd.DataFrame(data)
print(df.shape)
# 执行结果如下
(5, 3)size方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24, 26, 27, 33, 22]),
'Rating': pd.Series([4.23, 3.33, 4.11, 4.66, 5.24])}
df = pd.DataFrame(data)
print(df.size)
# 执行结果如下
15values方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24, 26, 27, 33, 22]),
'Rating': pd.Series([4.23, 3.33, 4.11, 4.66, 5.24])}
df = pd.DataFrame(data)
print(df.values)
# 执行结果如下
[['Tom' 24 4.23]
['James' 26 3.33]
['Ricky' 27 4.11]
['Vin' 33 4.66]
['Steve' 22 5.24]]head与tail方法
import pandas as pd
data = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve']),
'Age': pd.Series([24, 26, 27, 33, 22]),
'Rating': pd.Series([4.23, 3.33, 4.11, 4.66, 5.24])}
df = pd.DataFrame(data)
print(df.head())
# 执行结果如下
Name Age Rating
0 Tom 24 4.23
1 James 26 3.33DataFrame操作
自定义函数
import pandas as pd
import numpy as np
# 自定义函数
def adder(e1,e2):
return e1+e2
df = pd.DataFrame(np.random.randn(4,3),columns=['c1','c2','c3'])
# 通过pipe函数对DataFrame所有元素加3
df.pipe(adder,3)
# 通过apply函数对DataFrame的行或列进行操作
df.apply(np.mean) # 计算列平均值
df.apply(np.mean, axis=1) # 计算行平均值
# 通过applymap对逐个元素进行操作
print(df.applymap(lambda x: x * 100))
重置索引
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4, 3), columns=['c1', 'c2', 'c3'])
print(df)
# 根据列名与索引编号调整顺序
df = df.reindex(index=[0, 1, 3], columns=['c2', 'c1', 'c3'])
print(df)重命名标签
重命名行名与列名;
rename() 方法提供了一个 inplace 参数,默认值为 False,表示拷贝一份原数据,并在复制后的数据上做重命名操作。若 inplace=True 则表示在原数据的基础上重命名。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4, 3), columns=['c1', 'c2', 'c3'])
print(df)
df = df.rename(columns={'c1': 'A', 'c2': 'B', 'c3': 'B'}, index={0: 'row1', 1: 'row2', 2: 'row3', 3: 'row4'})
print(df)排序
DataFrame支持含找索引、列名、列值进行排序;
import pandas as pd
import numpy as np
# 行标签乱序排列,列标签乱序排列
unsorted_df = pd.DataFrame(np.random.randn(10, 2), index=[1, 6, 4, 2, 3, 5, 9, 8, 0, 7], columns=['col2', 'col1'])
# 按索引进行排序
sorted_df = unsorted_df.sort_index(ascending=False)
# 按列名进行排序
sorted_df = unsorted_df.sort_index(axis=1)
# 按列值进行排序
sorted_df = unsorted_df.sort_values(by='col1')
# 按指定算法进行排序
sorted_df = unsorted_df.sort_values(by='col1' ,kind='mergesort')sort_values() 提供了参数kind用来指定排序算法。这里有三种排序算法:
- mergesort
- heapsort
- quicksort
默认为 quicksort(快速排序) ,其中 Mergesort 归并排序是最稳定的算法。
去重
drop_duplicates()函数的语法格式如下:
df.drop_duplicates(subset=['A','B','C'],keep='first',inplace=True)
# subset:表示要去重的列名,默认为None
# keep:有三个可选参数,分别为first、last、False,
## 默认为first,表示保留第一次出现的重复项,删除其他重复项
## last表示保留最后一次出现的重复项,
## False表示删除所有重复项
# inplace:布尔值参数,默认为Flase表示删除重复项后返回一个副本,若为True则表示直接在原数据上删除重复项;import pandas as pd
data = {
'A': [1, 0, 1, 1],
'B': [0, 2, 5, 0],
'C': [4, 0, 4, 4],
'D': [1, 0, 1, 1]
}
df = pd.DataFrame(data=data)
print(df)
# 只有当两行完全相同时才会被去重
df = df.drop_duplicates()
print(df)
# 指定列名后,将以指定列值作为是否重复进行判断
df = df.drop_duplicates('B')
print(df)
# 指定多列名后,将以指定列值作为是否重复进行判断
df = df.drop_duplicates(['B','A'])
print(df)
数据选取
loc:基于标签索引选取数据,该函数具有以下访问方式
- 一个标量标签,如loc[‘a’]
- 标签列表,如loc[ [‘a’,’b’,’c’,’d’],[‘A’] ]
- 标签切片,如loc[‘a’:’c’],取值为前闭后闭区间
- 布尔数组,
iloc:基于整数索引选取数据,该函数具有以下访问方式 - 整数索引,如iloc[2:,]
- 整数列表,如iloc[ [1,3,5],[‘name’,’age’] ]
- 数值范围,如iloc[1:3,:],取值为前闭后开区间
import numpy as np
import pandas as pd
# 创建一组数据
data = {'name': ['John', 'Mike', 'Mozla', 'Rose', 'David', 'Marry', 'Wansi', 'Sidy', 'Jack', 'Alic'],
'age': [20, 32, 29, np.nan, 15, 28, 21, 30, 37, 25],
'gender': [0, 0, 1, 1, 0, 1, 0, 0, 1, 1],
'isMarried': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
label = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(data, index=label)
print(df)
print('************')
# loc([行号],[列名])
print(df.loc['a':'d', ['name', 'age']]) # 等同于df.loc['a':'d']
# iloc[行位置,[列位置]]
print(df.iloc[1:3,[1,2]])合并
Pandas 提供的 merge() 函数能够进行高效的合并操作,merge 翻译为“合并”,指的是将两个 DataFrame 数据表按照指定的规则进行连接,最后拼接成一个新的 DataFrame 数据表。
merge() 函数的法格式如下:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True)
# left/right:两个不同的DataFrame对象
# on:指定用于链接的键(列名称),该键需同时存在与两个DataFrame中;如未指定,则以两个DataFrame中所有相同类名作为关联键
# left_on:指定left用于关联的键名,需与right_on配合使用
# right_on:指定right用于关联的键名,需与left_on配合使用
# left_index:默认为False,若为True则使用行索引进行关联,如果有多层索引,需层的数量与连接键的数量相等;
# right_index:默认为False,如果True,则使用行索引作为连接键
# how:指定合并的类型,默认为inner,可选参数为{'left','right','outer','inner'}
# sort:默认为True,会将合并后数据进行排序,若设置为False,则按照how给定的参数值进行排序
# suffixes:字符串组成的元组,当左右DataFrame存在相同列名时,可通过该参数在相同列名后添加后缀,默认为('_x','_y')
# copy:默认为True,表示对数据进行复制import pandas as pd
left = pd.DataFrame({
'id': [1, 2, 3, 4],
'Name': ['Smith', 'Maiki', 'Hunter', 'Hilen'],
'subject_id': ['sub1', 'sub2', 'sub4', 'sub6']})
right = pd.DataFrame({
'id': [1, 2, 3, 4],
'Name': ['William', 'Albert', 'Tony', 'Allen'],
'subject_id': ['sub2', 'sub4', 'sub3', 'sub6']})
print(left)
print(right)
# 指定id作为关联键
print(pd.merge(left,right,on='id'))
# 指定多个字段作为关联键
print(pd.merge(left,right,on=['id','subject_id']))
# 指定关联方式
print(pd.merge(left, right, on='subject_id', how="left"))
print(pd.merge(left, right, on='subject_id', how="right"))
# 指定不同关联字段
right = right.rename(columns={'id': 'seq'})
print(pd.merge(left, right, left_on='id', right_on='seq'))连接
Pandas 通过 concat() 函数能够轻松地将 Series 与 DataFrame 对象组合在一起,函数的语法格式如下:
pd.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False)
# objs:一个序列或者Series、DataFrame对象
# axis:表示在哪个轴方向上进行链接,默认axis=0表示行方向
# join:指定链接方式,取值为{'inner','outer'},默认为outer表示取并集,inner表示取交集
# ignore_index:布尔值参数,默认为False,如果为True,表示不在链接的轴上使用索引
# join_axes:表示索引对象的列表新增列(函数赋值)
通过apply函数,根据已有列应用函数为新增列赋值;
import pandas as pd
import hashlib
data5 = {'four':{'a':4, 'b':5, 'c':6, 'd':7, 'e':8},
'one':{'a':1, 'b':2, 'c':3, 'd':4, 'e':5},
'three':{'a':3, 'b':4, 'c':5, 'd':6, 'e':7},
'two':{'a':2, 'b':3, 'c':4, 'd':5, 'e':6}}
df = pd.DataFrame(data5, index=list('abcde'), columns=['four', 'one', 'three', 'two'])
def md5(x,y):
str1 = x + y
hash_md5 = hashlib.md5()
hash_md5.update(str1)
return hash_md5.hexdigest()
# 其中添加if条件是为了避免出现error:must be convertible to a buffer, not Series
df['id'] = df.apply(lambda x: md5(x.four,x.one) if x.four >0 else 0,axis=1)
print(df)
##########################
four one three two id
a 4 1 3 2 3e27b3aa6b89137cce48b3379a2a6610
b 5 2 4 3 f5be5308b59e045b7c5b33ee8908cfb7
c 6 3 5 4 fcf5af2016adf65a97b579a67730f1b6
d 7 4 6 5 9e4a85729f78b2975359db968fd85c01
e 8 5 7 6 e8db777ce92139db987e9ac3a2e92eec
import pandas as pd
a = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
b = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D1', 'D2', 'D5', 'D6']},
index=[4, 5, 6, 7])
c = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B8', 'B9', 'B10', 'B7'],
'C': ['C9', 'C8', 'C7', 'C6'],
'D': ['D8', 'D5', 'D7', 'D6']},
index=[8, 9, 10, 11])
# 连接a与b,并对来自不同DataFrame的数据添加标签
print(pd.concat([a, b], keys=['x', 'y'], ignore_index=True))
# 横向连接
print(pd.concat([a, b], axis=1))
# 连接多个DataFrame
print(pd.concat[a, c, b])
文件读写
文件读取
当使用 Pandas 做数据分析的时,需要读取事先准备好的数据集,这是做数据分析的第一步。Panda 提供了多种读取数据的方法:
- read_csv() 用于读取文本文件
- read_json() 用于读取 json 文件
- read_sql_query() 读取 sql 语句结果
- read_excel() 用于读取excel文件
read_excel() 方法,其语法格式如下:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None, squeeze=False,dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0,
convert_float=True, **kwds)
# io: 表示Excel文件路径
# sheet_name:读取的工作表名称
# header:指定作为列名的行,默认为0,即取第一行的值为列名;若数据不包含列名,则设定header=None;若设定header=2,则表示前两行为多重索引
# names:一般适用于Excel缺少列名,或者需要重新定义列名的情况;names长度必须等于Excel表格列的长度,否则报错
# index_col:用作行索引的列,可以是工作表的列名称,如index_col='列名',也可以是整数或者列表
# usecols:int或list类型,默认为None,表示需要读取所有列
# squeeze:boolean,默认为False,如果解析的数据只包含一列,则返回一个Series
# converters: 规定每一列的数据类型
# skiprows:接受一个列表,表示跳过指定行数的数据,从头部第一列开始
# nrows:要读取的行数
# skipfooter:接受一个列表,省略指定行数的数据,从尾部最后一行开始import pandas as pd
# 指定跳过前N行
df1 = pandas.read_csv('C:/Users/Administrator/Desktop/hrd.csv',skiprows=2)
df2 = pd.read_json('C:/Users/Administrator/Desktop/hrd.json')
df3 = pd.read_sql_query("SELECT * FROM information",con)
# 读取excel数据
# index_col选择前两列作为索引列
# 选择前三列数据,name列作为行索引
df = pd.read_excel('website.xlsx', index_col='name', index_col=[0, 1], usecols=[1, 2, 3])
# 处理未命名列,固定用法
df.columns = df.columns.str.replace('Unnamed.*', 'col_label')文件写出
to_csv:Pandas 提供的 to_csv() 函数用于将 DataFrame 转换为 CSV 数据。如果想要把 CSV 数据写入文件,只需向函数传递一个文件对象即可。否则,CSV 数据将以字符串格式返回。
to_excel:通过 to_excel() 函数可以将 Dataframe 中的数据写入到 Excel 文件。如果想要把单个对象写入 Excel 文件,那么必须指定目标文件名;如果想要写入到多张工作表中,则需要创建一个带有目标文件名的ExcelWriter对象,并通过sheet_name参数依次指定工作表的名称。
to_ecxel() 语法格式如下:
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
# excel_writer:文件路径或者ExcelWrite对象
# sheet_name:指定要写入数据的工作表名称
# na_rep:缺失值的表示形式
# float_format:它是一个可选参数,用于格式化浮点数字符串
# columns:指定要写入的列
# header:写出每一列的列名,如果给出的是字符串列表,则表示列的别名
# index:表示要写入的索引
# index_label:引用索引列的列标签,如果未指定,并且header和index均为True,则使用索引名称;如果DF使用MultiIndex,则需要给出一个序列
# startrow:初始写入的行位置,默认为0;表示引用左上角行单元格来存储DF
# startcol:初始写入的列位置,默认为0;表示引用左上角的列单元格存储DF
# engine:它是一个可选参数,用于指定要使用的引擎,可以是openpyxl或xlswriterimport pandas as pd
#创建DataFrame数据
info_website = pd.DataFrame({'name': ['编程帮', 'c语言中文网', '微学苑', '92python'],
'rank': [1, 2, 3, 4],
'language': ['PHP', 'C', 'PHP','Python' ],
'url': ['www.bianchneg.com', 'c.bianchneg.net', 'www.weixueyuan.com','www.92python.com' ]})
#创建ExcelWrite对象
writer = pd.ExcelWriter('website.xlsx')
info_website.to_excel(writer)
writer.save()
print('输出成功')
