Spark基本概念
Application
指用户编写的程序代码;
Driver
表示main函数,创建SparkContext,并由SC负责与ClusterManager通信,进行资源的申请,任务监控和分配;程序运行结束后,关闭SparkContext;
Executor
Application运行在Worker或NM节点上的一个进程,负责运行具体的task,并将计算的结果数据存储在内存或硬盘上。Spark on Yarn模式下,其进程名为CoarseGrainedExecutorBackend,一个CoarseGrainedExecutorBackend进程有且仅有一个Executor对象,负责将task包装成taskrunner,并从线程池抽取空闲线程运行task;因此,每个CoarseGrainedExecutorBackend能并发运行的task数量取决于分配的CPU个数;
Task
在Executor进程中任务执行的工作单元,多个task组成一个Stage;
Job
包含多个task组成的并行计算,由action算子触发;
Stage
每个Job任务会被拆分成多个Task,组合成多个TaskSet,每个TaskSet定义为一个Stage;
DAGScheduler
根据 Job将DAG划分成不同的Stage,并提交Stage给TaskScheduler,Stage划分依据为RDD的依赖关系;
TaskScheduler
将TaskSet提交给worker/NM运行,每个Executor运行什么Task就是在此处分配;
SchedulerBackend
是一个trait,作用是分配当前可用资源,具体 就是想当前等待分配计算资源的task分配资源,即Executor,并在分配的Executor中启动task,完成计算调度;
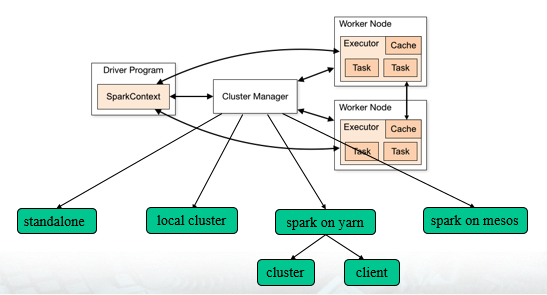
Spark运行模式
Spark任务运行可分为四种模式:Local Cluster、Standalone、Spark on Yarn及Spark on Mesos;
Standalone模式
即Spark自带的独立模式,自带完整服务,可单独部署到一个集群中,无需依赖其他资源管理系统,但只支持FIFO调度器;用户节点直接与Master交互,由Driver负责资源调度与分配;从一定程度上可以说是Spark on Yarn和Spark on Mesos的基础。
Local Cluster模式
Standalone模式的单机版,Master与Worker运行在同一台机器的不同进程上,一般用本地测试;
Spark on Yarn
这是一种很有前景的部署模式,目前生产环境大多数都为该模式。限于Yarn自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。这是由于Yarn上的container无法动态伸缩,一旦container启动之后,可用资源就不能再变更。Spark on Yarn支持两种任务提交模式:
- cluster:适用于生产环境;
- client:适用于交互、调试模式,可立刻看到任务的输出信息;
Spark on Mesos
官方推荐的模式,Spark开发之初就考虑支持Mesos,因此,目前节点Spark运行在Mesos上会比Yarn更加灵活、自然。Spark on Mesos支持两种调度模式:
- 粗粒度模式:类似于APP运行于一个Mesos临时搭建的虚拟Yarn集群上;
- 细粒度模式:类似于现在的云计算,思想是按需分配;应用程序启动后,会先启动Executor,但每个Executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,Mesos会为每个Executor动态分配资源,每分配一部分资源,便会启动一个新任务,单个任务运行结束后马上释放对应的资源。每个任务会汇报状态给Mesos Slave和Mesos Master,便于更加细粒度管理与容错,这种调度模式类似于MR模式,每个任务完全独立,优点是便于资源控制和格力,但缺点也明显,短作业运行延迟大;
Spark任务运行过程
Yarn-cluster模式
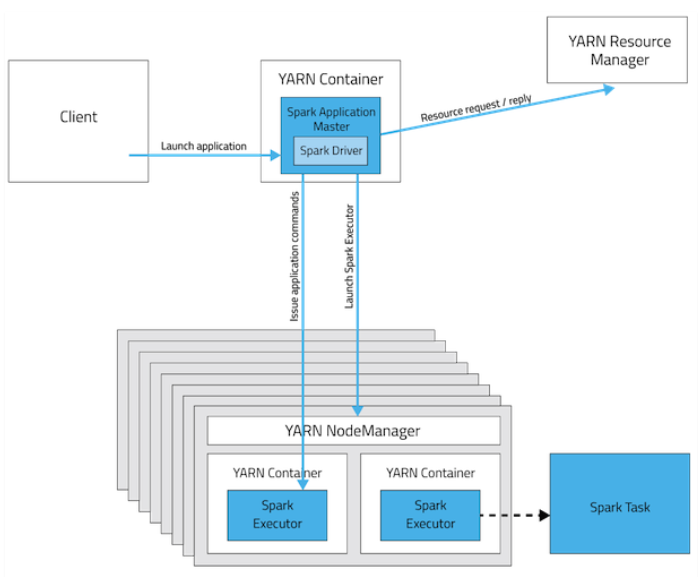
- Spark Client向Yarn RM提交请求启动ApplicationMaster,上传Jar包到HDFS上;
- RM收到请求后,在集群中选择一个NM节点,为该应用程序分配第一个Container,要求它在这个Container中启用应用程序的ApplicationMaster,由ApplicationMaster进行SparkContext等的初始化;
- ApplicationMaster向RM注册,便于用户直接通过RM查看应用程序的运行状态,AM采用轮询方式通过RPC协议为各个任务申请资源,并监控其运行状态知道运行结束;
- 一旦ApplicationMaster申请到资源后,便与对应的NM通信,要求申请到的Container启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task;
- ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以便让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时进行重试;
- Application运行完成后,ApplicationMaster向RM申请注销并关闭自己;
Yarn-client模式
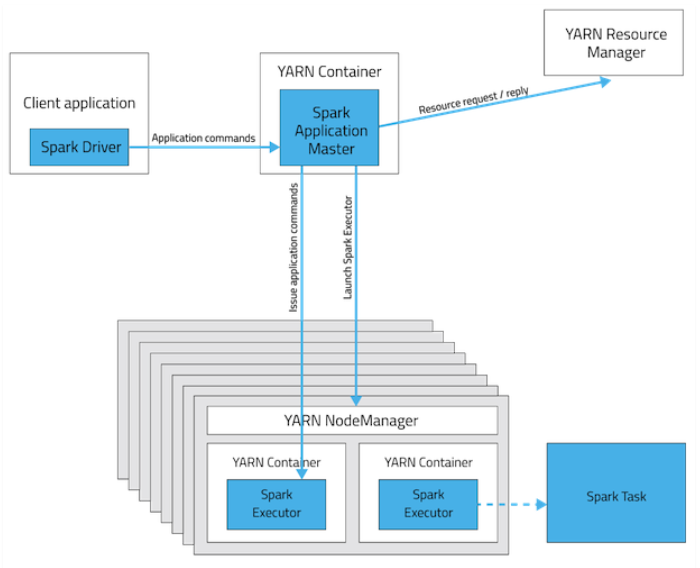
- Spark Client在本地启动Driver,并进行应用程序实例化SparkContext,同时在SparkContext中创建DAGScheduler和TaskScheduler等;
- Spark Client向RM提交请求启动ApplicationMaster,上传Jar包到HDFS上;
- RM收到请求后,在集群中选择一个NM节点,并为应用程序分配第一个Container,要求它在这个Container启动应用程序的ApplicationMaster;ApplicationMaster只负责与SparkContext联系进行资源分派;
- SparkContext初始化完毕后,与ApplicationMaster建立通信,由ApplicationMaster向RM注册,并根据任务信息向RM申请资源(Container);
- ApplicationMaster申请到资源(Container)后,便于对应的NM通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后向Client中的SparkContext注册并申请Task;
- Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以便Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
- 应用程序运行完成后,Client的SparkContext向RM申请注销并关闭自己.
Yarn-client与Yarn-cluster区别:
- Cluster模式下,Driver运行在AM中,用户提交作业后就可以关闭Client,作业会继续在Yarn上运行;
- Client模式下,Driver运行在本地,AM仅负责向Yarn请求Executor,Client会和请求的Container通信调度Task运行;

