核心组件
Flink四大核心组件为:State、Checkpoint、Window及Time;
State
State即状态管理,一般有两种存在形式,RawState及ManageState;
RawState
原始状态,由用户自行管理状态具体的数据结构及序列化,框架在进行checkpoint时,使用byte[]来读写内容,对其内部数据结构一无所知,常用于自定义operator时使用;
ManageState
托管状态,由flink框架管理状态,自动存储、自动恢复,且在内存管理上存在一定的优化,能够在大多数场景下使用,非自定义operator时推荐使用托管状态;
Checkpoint
状态保存与恢复
Checkpoint定时制作分布式快照,对程序中的状态进行备份;发生故障时,将整个作业的所有task都回滚到最后一次成功Checkpoint中的状态,然后从该点重新开始处理(需数据源支持重发);
状态存储方式
State的store和Checkpoint的位置取决于stateBackend的配置
- MemoryStateBackend:state的数据保存在taskManager的内存中,执行Checkpoint时,将state快照保存到JobManager的内存中;基于内存存储方式,一旦停机或程序崩溃,状态数据将丢失且无法恢复,生产环境不建议使用;单个state大小默认为5M,推荐用于本地测试;
- FsStateBackend:state的数据保存在taskManager的内存中,执行Checkpoint时,将state快照保存到配置的文件系统中,常用文件系统为HDFS;推荐用于常规状态作业;
- RocksDBStateBackend:在本地文件系统中维护一个状态,state直接写入本地RockDB,同时需要配置一个源端FS URI(一般为HDFS),执行Checkpoint时,将本地数据复制到远端FS中,Failover时从远端FS中恢复至本地;单key状态最大不超过2G,推荐用于超大状态的作业,可用于对状态读写性能不高的生产场景;
Checkpoint与savePoint
Checkpoint
- Flink自动出发并管理,主要用于Task异常时快速恢复;
- 轻量级,作业停止后默认清除;
savePoint
- 用户手动触发并管理,主要用户升级备份等,作业能够停止后恢复;
- 持久化,以标准格式存储,允许代码或配置发生变更,手动触发从savePoint的恢复;
作业重启策略
Flink支持不同的重启策略,以便在顾上发生时快速恢复;集群启动时会伴随一个默认的重启策略,在作业没有定义具体重启策略时会使用集群的默认重启策略;当作业配置了重启策略时,该策略会覆盖集群默认重启策略;常用的重启策略有:固定间隔、失败率及无重启;
- 如果没有启用Checkpointing,则使用无重启策略;
- 如果启用了Checkpointing,但未配置重启策略,则默认使用固定间隔策略,其中Integer.MAX_VALUE参数是尝试重启次数;
Window
Window按照触发方式可分为Time Window、Count Window及自定义Window;按照窗口类型可分为滑动窗口(tumbling window)与滚动窗口(sliding window);
Time Window
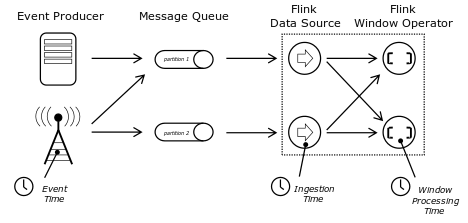
最简单常用的窗口形式是基于时间触发的窗口;时间可分为EventTime、IngestTime及ProcessTime;
EventTime 事件时间、日志时间
IngestTime 进入 Flink 的时间(进入datasource的时间)
ProcessingTime Flink 处理的时间
Count Window
基于事件数量触发的窗口;
Tumbling Window
将数据根据固定敞口大小进行切割计算;
特点:时间对齐,窗口大小固定,适合进行BI统计等场景;
Sliding Window
窗口间元素可能存在重叠,由窗口大小及滑动步长组成;
特点:窗口大小固定,不同窗口间可能存在重叠,适合进行监控报警等场景;

