Hadoop简介
Hadoop是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,实现在大量计算机组成的集群中对海量数据进行分布式计算。适合大数据的分布式存储和计算平台。
Hadoop1.x中包括两个核心组件:MR(MapReduce)和HDFS(Hadoop Distributed File System)。
- HDFS负责将海量数据进行分布式存储;
- MR负责提供对数据的计算结果的汇总;
Hadoop起源
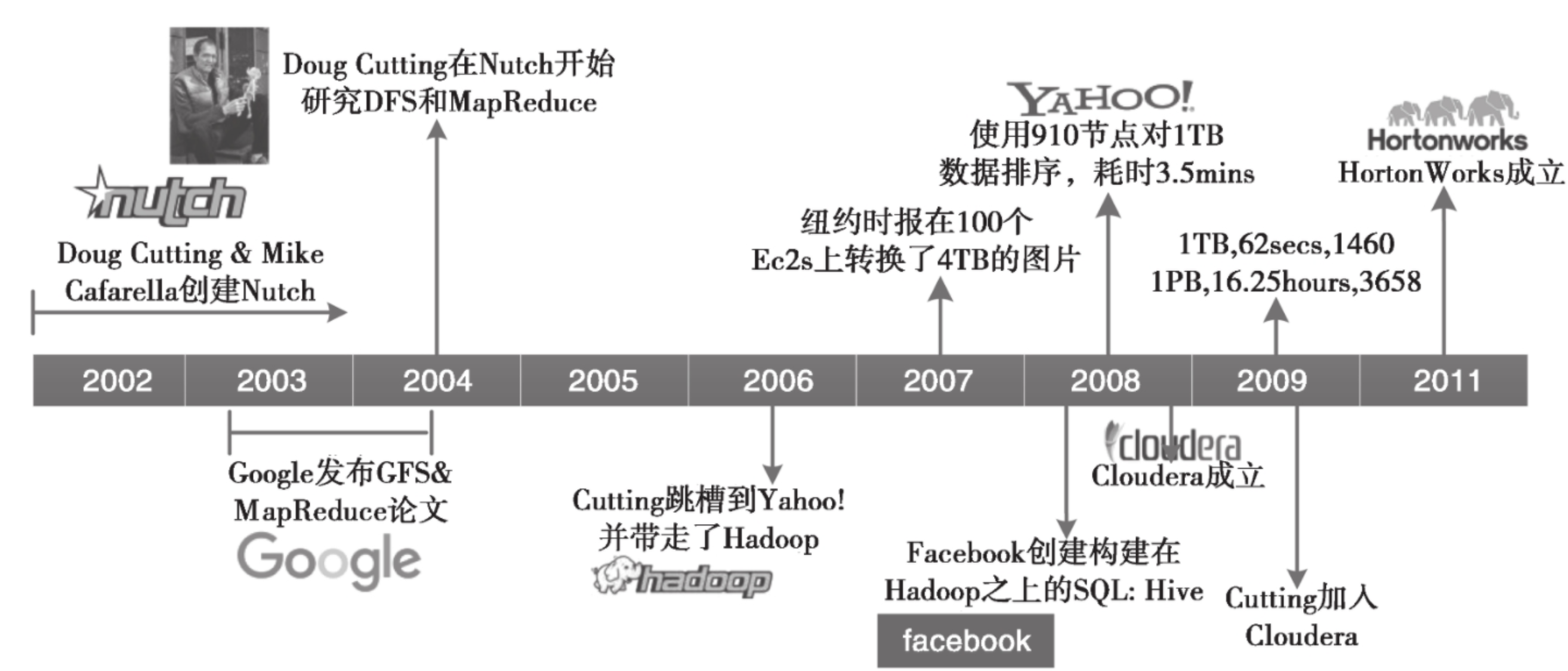
2002~2004 年,第一轮互联网泡沫刚刚破灭,很多互联网从业人员都失业了。我们的“主角” Doug Cutting 也不例外,他只能写点技术文章赚点稿费来养家糊口。但是 Doug Cutting 不甘寂寞,怀着对梦想和未来的渴望,与他的好朋友 Mike Cafarella 一起开发出一个开源的搜索引擎 Nutch,并历时一年把这个系统做到能支持亿级网页的搜索。但是当时的网页数量远远不止这个规模,所以两人不断改进,想让支持的网页量再多一个数量级。
在 2003 年和 2004 年, Googles 分別公布了 GFS 和 Mapreduce 两篇论文。 Doug Cutting 和 Mike Cafarella 发现这与他们的想法不尽相同,且更加完美,完全脱离了人工运维的状态,实现了自动化。
在经过一系列周密考虑和详细总结后,2006 年, Dog Cutting 放奔创业,随后几经周折加入了 yahoo 公司(Nutch 的部分也被正式引入),机绿巧合下,他以自己儿子的一个玩具大象的名字 Hadoop 命名了该项。
当系统进入 Yahoo 以后,项目逐渐发展并成熟了起来。首先是集群规模,从最开始几十台机器的规模发展到能支持上千个节点的机器,中间做了很多工程性质的工作;然后是除搜索以外的业务开发, Yahoo 逐步将自己广告系统的数据挖掘相关工作也迁移到了 Hadoop 上,使 Hadoop 系统进一步成熟化了。
2007 年,纽约时报在 100 个亚马逊的虚拟机服务器上使用 Hadoop 转换了 4TB 的图片数据更加加深了人们对 Hadoope 的印象。
在 2008 年的时侯,一位 Google 的工程师发现要把当时的 Hadoop 放到任意一个集群中去运是一件很困难的事情,所以就与几个好朋友成立了ー个专门商业化 Hadoop 的公司 Cloudera。同年, Facebook 团队发现他们很多人不会写 Hadoop 的程序,而对 SQL 的一套东西很熟,所以他们就在 Hadoop 上构建了一个叫作 Hive 的软件,专把 SQL 转换为 Hadoop 的 Mapreduce 程序。
2011年, Yahoo 将 Hadoop 团队独立出来,成立了ー个子公司 Hortonworks,专门提供 Hadoop 相关的服务。
Hadoop的发展历史如下图:
Hadoop特性
特点
错误检测与自动恢复
大规模数据集
流式数据访问
简单一致性模型
移动计算
优点
Rellable:高可靠性,能够自动维护数据的多副本,并在任务执行失败时自动重新分配;
Scalabel:高扩展性,Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可以方便的进行横向扩展;
Efficient:高效率,Hadoop能够在集群节点之间动态地移动数据,保证各个节点的动态平衡,提升处理速度;
Economical:Hadoop是开源的,并且Hadoop可以运行于普通X86主机上,能大大降低项目成本;
缺点
不适合低延迟业务场景;
不适合大量小文件存储;
不支持随机修改,仅支持文件末尾追加;
不支持并发写入;

