Hadoop功能架构
Hadoop构成
Hadoop主要由三个功能模块组成,分布式文件存储系统HDFS,分布式计算框架MapReduce以及资源调度框架Yarn。
Hadoop 2.x 时代,将JobTracker 从MapReduce中分离出来,重新设计后专门用于资源调度,即Yarn资源调度框架;
HDFS
HDFS(Hadoop Distributed File System)是分布式存储系统,对客户端而言,HDFS与传统的分级文件系统没有区别,可以按照Linux文件系统一样进行创建、删除、移动文件/文件夹等操作;
NameNode
Namenode简称NN,作为集群中的主节点,主要负责三个功能:
管理元数据:负责管理维护整个HDFS文件系统命令空间;
维护目录树:维护文件系统树和树内所有的文件及目录,这些信息以检查点镜像(FsImage)及操作日志(Editslog)形式持久化至NN节点本地磁盘中;
响应客户端请求:负责处理客户端与HDFS交互;
Fsimage
NN会定期对当前HDFS元数据信息进行序列化后快照,快照文件有两种状态,finalized和checkpoint, finalized表示已经持久化磁盘的文件,文件名形式: fsimage_[end-txid], 同时会生成一个同名md5校验文件;checkpoint表示合并中的fsimage;Fsimage文件一般包含以下内容:
Image head:
- imgVersion(int):当前image的版本信息;
- namespaceID(int):用来确保别的HDFS instance中的datanode不会误连上当前NN
- numFiles(long):整个文件系统中包含有多少文件和目录
- genStamp(long):生成该image时的时间戳信息。
Resource Info:
path(String):该目录的路径(该路径为HDFS路径),如”/user/build/build-index”
replications(short):副本数(目录虽然没有副本,但这里记录的目录副本数也为3)
mtime(long):该目录的修改时间的时间戳信息
atime(long):该目录的访问时间的时间戳信息
blocksize(long):目录的blocksize都为0
numBlocks(int):实际有多少个文件块,目录的该值都为-1,表示该item为目录
nsQuota(long):namespace Quota值,若没加Quota限制则为-1
dsQuota(long):disk Quota值,若没加限制则也为-1
username(String):该目录的所属用户名
group(String):该目录的所属组
permission(short):该目录的permission信息,如644等,有一个short来记录。
- blockid(long):block的blockid
- numBytes(long):该block的大小
- genStamp(long):该block的时间戳

EditLog
操作日志文件,操作日志文件分为两类:
- finalized:已完成写入并滚动的日志文件,命名规则为edits_[start-txid]-[end-txid],该文件中记录了start-txid到end-txid之间的HDFS元数据变更记录;
- inprogress:正在写入的日志文件,命名规则为edits_inprogress_start-txid,该文件记录了从start-txid开始的HDFS元数据变更记录;
- 标记文件:文件名为seen_txid,保存的是一个事务ID,这个事务ID是EditsLog最新的一个结束事务id,当NameNode重启时,会顺序遍历所有Fsimage对应事务ID后EditLog以及edits_inprogress_start-txid到seen_txid所记录的txid所在的日志文件,进行元数据恢复,如果该文件丢失或记录的事务ID有问题,会造成数据块信息的丢失;
Namenode一条元数据信息大小大概为150 Byte。
NameNode HA
NameNode在HDFS中是一个非常重要的组件,相当于HDFS文件系统的心脏,在分布式集群环境中,还是会有可能出现NameNode的崩溃或各种意外,将导致整个集群不可用。所以,Hadoop演进至2.x阶段实现了NameNode HA(High Availability)架构:
Active NN:
- 响应客户端请求;
- 记录EditLog并同步至JN;
- 接收DN的heartbeat及Block Report;
Standby NN:
- 读取JN上EditLog信息;
- 接收DN的heartbeat及Block Report;
- 合并Fsimage及EditLog,生成新的Fsimage;
JounalNode:
- 日志同步:保障Active NN与Standby NN元数据一致;
- 双写隔离:避免多个NN同时写入EditLog;
- 日志恢复:当出现故障时,完成节点上不一致日志的恢复,避免操作记录丢失;
ZKFC:
- 监控NN健康状态;
- 定期发送心跳至ZK;
- 自动故障转移;
Zookeeper:
- 失败保护:NN与Zookeeper会维护一个长连接session,一旦服务异常,session将会过期,触发故障迁移;
- 服务选举:当Active NN的session过期后,Standby NN将会向NN申请排他切换为Active NN节点;
- 防脑裂:通过ZK本身的强一致和高可用特性,保证同一时刻只有一个活动节点,即Active NN节点;
Checkpoint触发的条件有两个:
- 时间间隔:由参数dfs.namenode.checkpoint.period控制,默认为3600s;
- 处理事务数:由参数dfs.namenode.checkpoint.txns控制,默认为1000000;
Fsimage滚动条件:
- 每次checkpoint会生成一个新的Fsimage;
- 每次NN重启会生成一个新的Fsimage;
- 由参数dfs.namenode.num.checkpoints.retained控制Fsimage保留数量,默认为2;
EditLog滚动条件:
- 时间间隔:由参数dfs.namenode.edit.log.autoroll.check.interval.ms控制,默认为300000ms;
- 处理事务数:由参数dfs.namenode.edit.log.autoroll.multiplier.threshold * dfs.namenode.checkpoint.txns 控制,dfs.namenode.edit.log.autoroll.multiplier.threshold默认值为2.0f;
HA模式滚动条件:
- EditLog滚动周期:由参数dfs.ha.log-roll.period控制,默认为120s,Standby NN按照周期让Active NN进行EditLog滚动;
- EditLog合并周期:由参数dfs.ha.tail-edits.period控制,默认为60s,Standby NN按照周期去检测已完成的EditLog,并抓取文件通过JN读取到内存中更新Fsimage状态;
- EditLog存储事务数:由参数dfs.namenode.num.extra.edits.retained控制,默认为1000000;
常见触发NN主备切换场景:
- Active NN JVM崩溃:ANN上HealthMonitor状态上报会有连接超时异常,HealthMonitor会触发状态迁移至SERVICE_NOT_RESPONDING, 然后ANN上的ZKFC会退出选举,SNN上的ZKFC会获得Active Lock, 作相应隔离后成为Active结点。
- Active NN GC超时:当GC时间超出健康检查时长时,同样会触发自动切换;
- Active NN 宕机:此时ActiveStandbyElector会失去同ZK的心跳,会话超时,SNN上的ZKFC会通知ZK删除ANN的活动锁,作相应隔离后完成主备切换。
- Active NN健康状态异常:此时HealthMonitor会收到一个HealthCheckFailedException,并触发自动切换。
- Active NN节点ZKFC崩溃:一旦ZKFC进程挂掉,虽然此时NameNode是OK的,但系统也认为需要切换,此时SNN会发一个请求到ANN要求ANN放弃主结点位置,ANN收到请求后,会触发完成自动切换。
- Zookeeper崩溃:如果ZK奔溃了,主备NN上的ZKFC都会感知断连,此时主备NN会进入一个NeutralMode模式,同时不改变主备NN的状态,继续发挥作用,只不过此时,如果ANN也故障了,那集群无法发挥Failover, 也就不可用了,所以对于此种场景,ZK至少要有N/2+1台保持服务才算是安全的。

Hadoop高可用详细解析可参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/
DataNode
DataNode简称DN,主要负责以下工作:
- 以Block形式存储HDFS文件;
- 响应HDFS客户端读写请求;
- 周期性向NN汇报heartbeat及Block Report信息,缓存Block信息;
HDFS Federation
什么是Federation机制
HDFS Federation 是解决 namenode 内存瓶颈问题的水平横向扩展方案;通过使用多个独立的NameSpace(NameNode节点管理)各自管理一部分元数据,且共享所有DataNode存储资源;
- NameNode:相互独立且不需要互相协调,各自独立分工。
- DataNode:向集群中所有NameNode注册,周期性向所有NameNode发送心跳和BlockReport并响应所有NameNode的请求;
Federation 架构设计
HDFS 1.x时代主要由NameSpace和Block Storage两层组成,通过NameNode进行元数据存储与管理,DataNode进行Block的读写与存储。结构如下图:
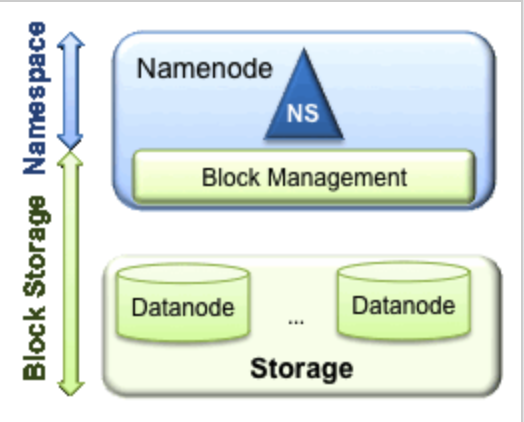
HDFS 1.x的存在以下局限性:
- NameSpace限制:namenode把所有元数据存储在内存中,单个NameNode所能存储的对象(文件+块)有限制;
- 性能瓶颈:整个hdfs文件系统的吞吐量受限于单个NameNode的吞吐量;
- 隔离问题:无法隔离应用程序,一个实验程序,可能影响整个集群;
- 单点故障:一旦NameNode故障将导致整个集群不可用;
Q:单机NameNode的瓶颈是多少呢?
A:大约是在4000台集群。
Q:为什么不考虑进行纵向扩展呢?
- 纵向扩展将导致NN启动时间线性增加;
- FullGC异常可能导致整个集群不可用;
- 大JVMHeap调试困难;
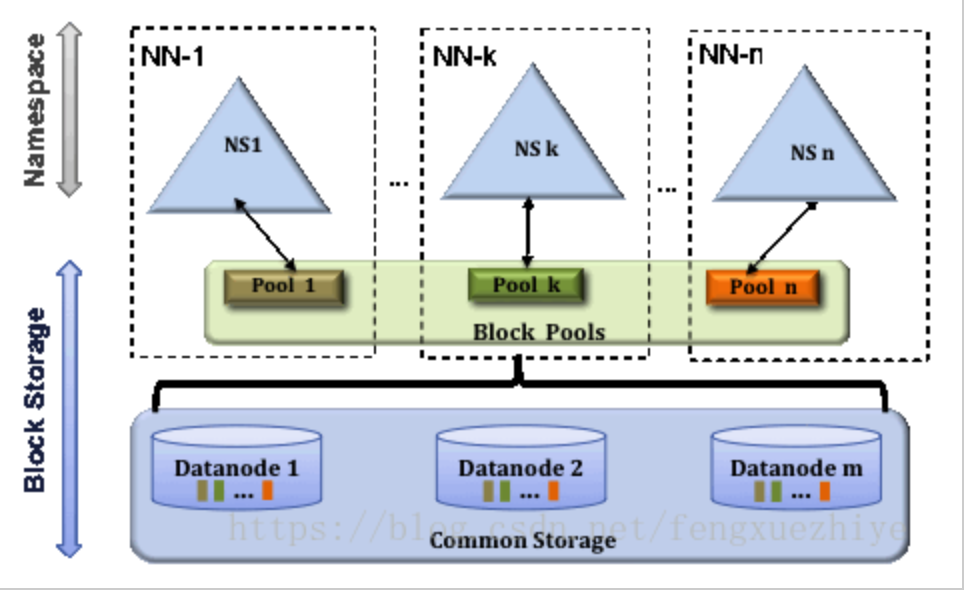
HDFS 2.x时代逐步演进为NameSpaces、Block Pools和Common Storeage三层Federation架构,NameSpace之间相互独立,各自分工管理自己的Block Pool,且不需要互相协调;Block Pool内部自制,不需要与其他Block Pool交流;Federation架构的优势体现在:
- HDFS集群扩展性:每个NameNode分管一部分namespace,相当于NameNode是一个分布式的。
- 性能更高效:多个NameNode同时对外提供服务,提供更高的读写吞吐率。
- 良好的隔离性:用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
- Federation良好的向后兼容性:已有的单NameNode的部署配置不需要任何改变就可以继续工作。
Federation不足:
【单点故障问题】
HDFS Federation并没有完全解决单点故障问题。虽然NameNode/namespace存在多个,但是从单个NameNode/namespace看,仍然存在单点故障:如果某个NameNode挂掉了,其管理的相应的文件便不可以访问。Federation中每个NameNode仍然像之前HDFS上实现一样,配有一个Secondary NameNode,以便主namenode挂掉一下,用于还原元数据信息。
【负载均衡问题】
HDFS Federation采用了Client Side Mount Table分摊文件和负载,该方法更多的需要人工介入已达到理想的负载均衡。
Federation关键技术点
命名空间管理
Federation中存在多个命名空间,如何划分和管理这些命名空间非常关键。在Federation中并采用“文件名hash”的方法,因为该方法的locality非常差,比如:查看某个目录下面的文件,如果采用文件名hash的方法存放文件,则这些文件可能被放到不同namespace中,HDFS需要访问所有namespace,代价过大。为了方便管理多个命名空间,HDFS Federation采用了经典的Client Side Mount Table。
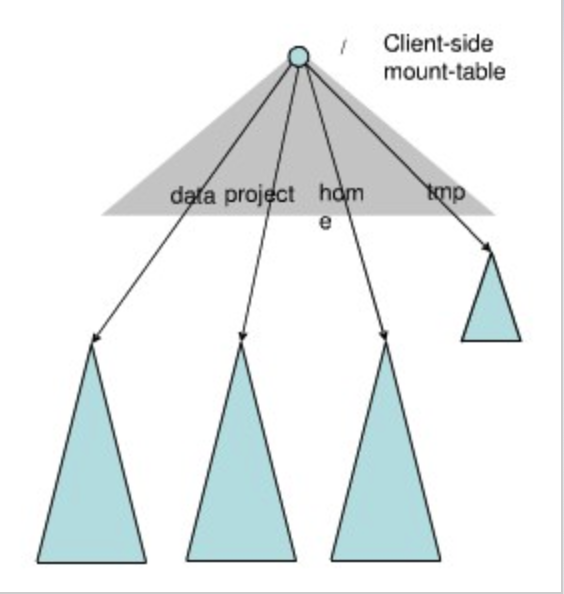
如上图所示,下面四个深色三角形代表一个独立的命名空间,上方浅色的三角形代表从客户角度去访问的子命名空间。各个深色的命名空间Mount到浅色的表中,客户可以访问不同的挂载点来访问不同的命名空间,这就如同在Linux系统中访问不同挂载点一样。这就是HDFS Federation中命名空间管理的基本原理:将各个命名空间挂载到全局mount-table中,就可以做将数据到全局共享;同样的命名空间挂载到个人的mount-table中,这就成为应用程序可见的命名空间视图。
Federation配置
假设你的集群中有三个namenode,分别是namenode1,namenode2和namenode3,其中,namenode1管理/usr和/tmp两个目录,namenode2管理/projects/foo目录,namenode3管理/projects/bar目录,则可以创建一个名为“cmt”的client-side mount table,并在mountTable.xml中进行如下配置:
<configuration>
<property>
<name>fs.viewfs.mounttable.cmt.link./user</name>
<value> hdfs://namenode1:9000/user </value>
</property>
<property>
<name>fs.viewfs.mounttable.cmt.link./tmp</name>
<value> hdfs:/ namenode1:9000/tmp </value>
</property>
<property>
<name>fs.viewfs.mounttable.cmt.link./projects/foo</name>
<value> hdfs://namenode2:9000/projects/foo </value>
</property>
<property>
<name>fs.viewfs.mounttable.cmt.link./projects/bar</name>
<value> hdfs://namenode3:9000/projects/bar</value>
</property>
</configuration>Client-side mount table的引入为用户使用HDFS带来极大的方便,尤其是跨namenode的数据访问。

